大规模多任务语言理解基准
MMLU 全称 Massive Multitask Language Understanding,是一种针对大模型的语言理解能力的测评,是目前最著名的大模型语义理解测评之一,由UC Berkeley大学的研究人员在2020年9月推出。该测试涵盖57项任务,包括初等数学、美国历史、计算机科学、法律等。任务涵盖的知识很广泛,语言是英文,用以评测大模型基本的知识覆盖范围和理解能力。
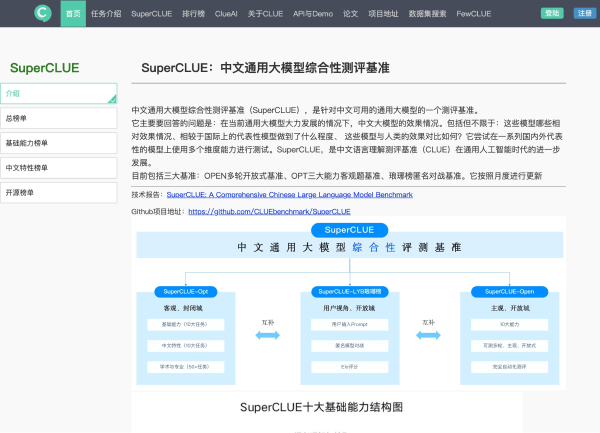
中文通用大模型综合性测评基准
一个综合性的大模型中文评估基准
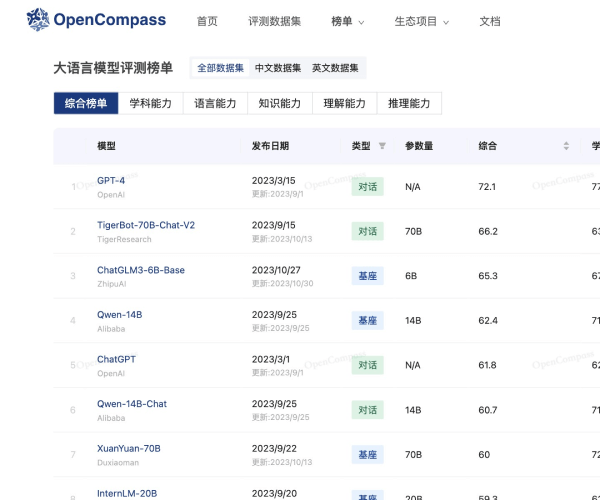
上海人工智能实验室推出的大模型开放评测体系
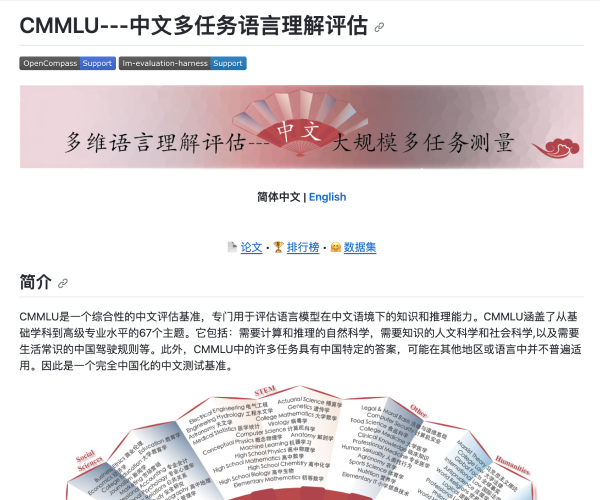
一个全面的中文基础模型评估套件
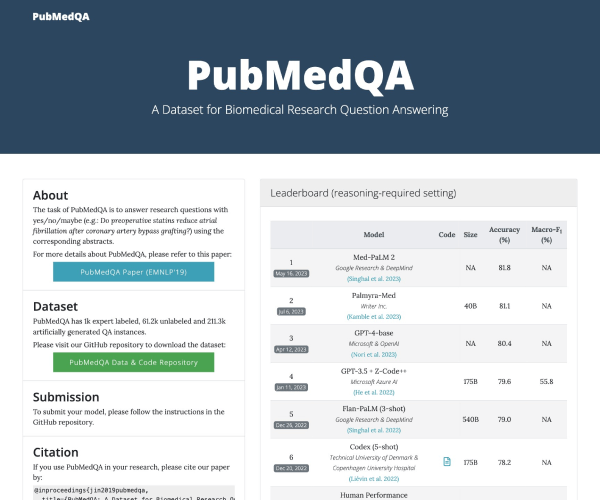
生物医学研究问答数据集和模型得分排行榜
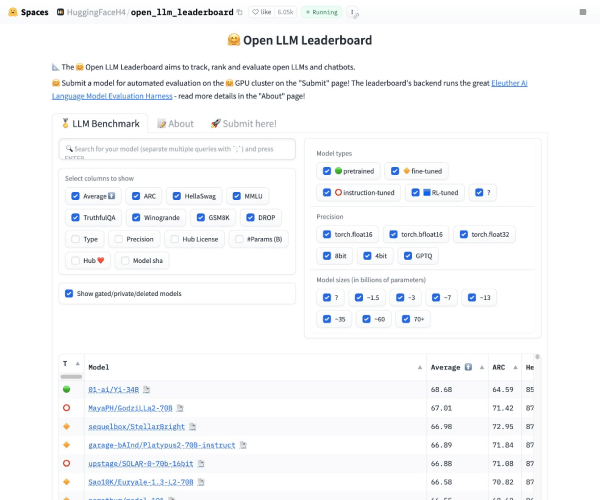
Hugging Face推出的开源大模型排行榜单