












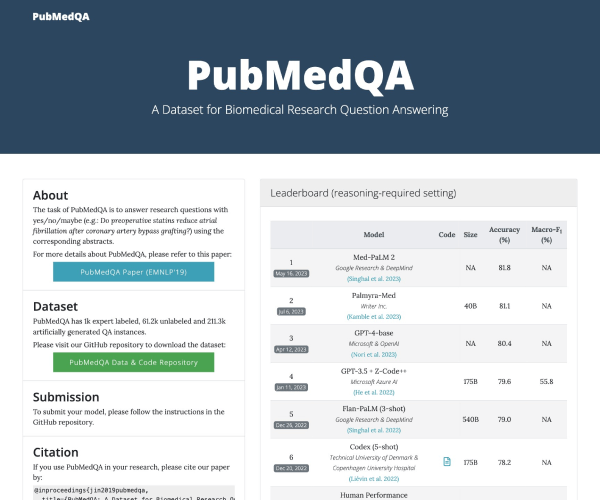
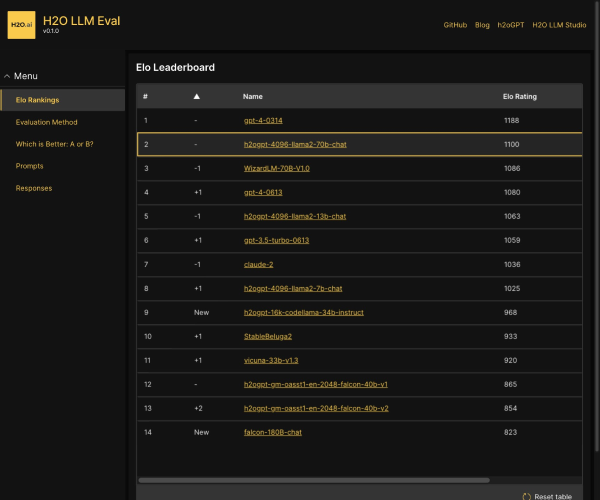
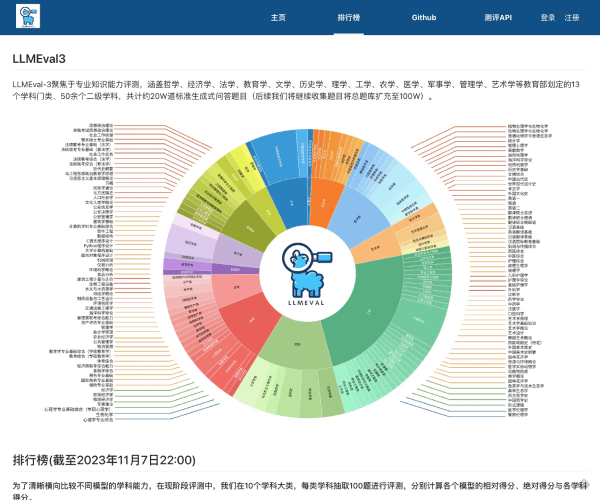
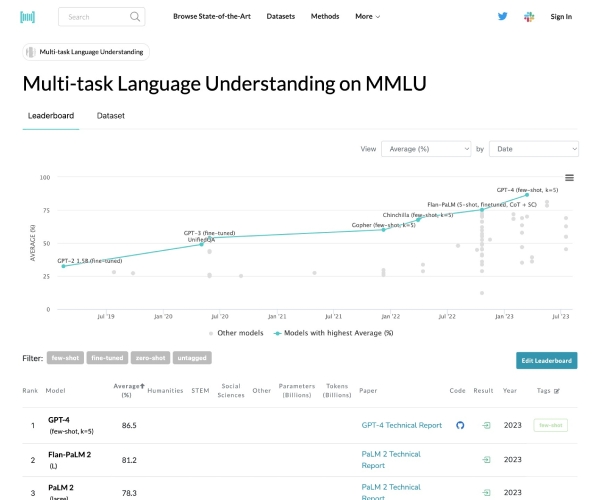
Open LLM Leaderboard 是最大的大模型和数据集社区 HuggingFace 推出的开源大模型排行榜单,基于 Eleuther AI Language Model Evaluation Harness(Eleuther AI语言模型评估框架)封装。
由于社区在发布了大量的大型语言模型(LLM)和聊天机器人之后,往往伴随着对其性能的夸大宣传,很难过滤出开源社区取得的真正进展以及目前的最先进模型。因此,Hugging Face 使用 Eleuther AI语言模型评估框架对模型进行四个关键基准测试评估。这是一个统一的框架,用于在大量不同的评估任务上测试生成式语言模型。
Open LLM Leaderboard 的评估基准
相关导航
暂无评论...