一个综合性的大模型中文评估基准
CMMLU是一个综合性的中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力,涵盖了从基础学科到高级专业水平的67个主题。它包括:需要计算和推理的自然科学,需要知识的人文科学和社会科学,以及需要生活常识的中国驾驶规则等。此外,CMMLU中的许多任务具有中国特定的答案,可能在其他地区或语言中并不普遍适用。因此是一个完全中国化的中文测试基准。
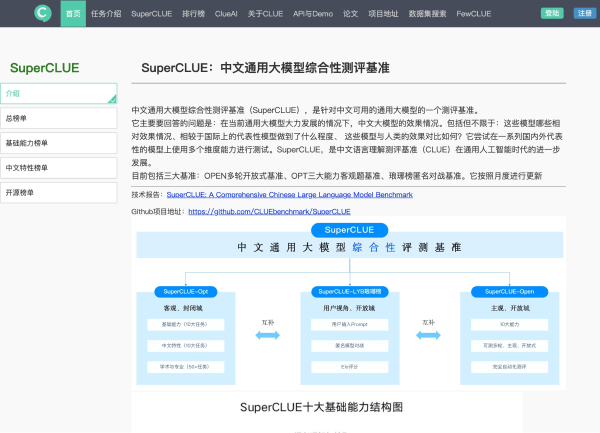
中文通用大模型综合性测评基准
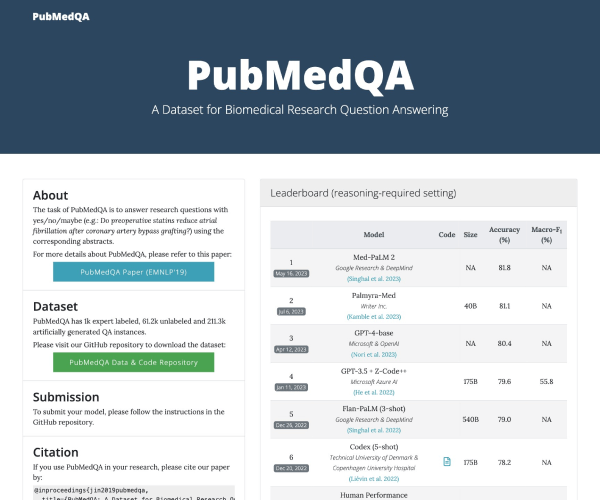
生物医学研究问答数据集和模型得分排行榜
斯坦福大学推出的大模型评测体系
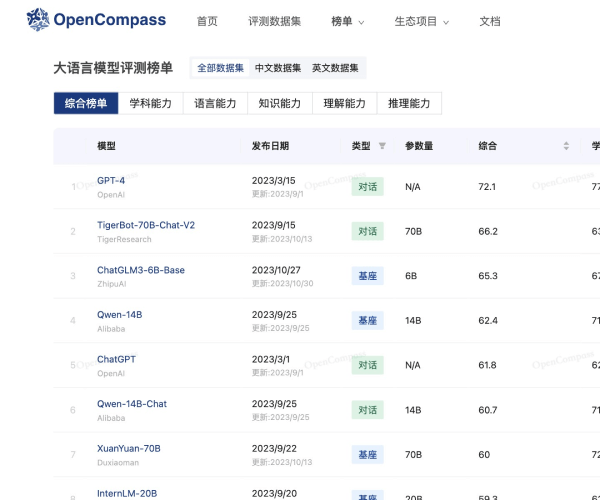
上海人工智能实验室推出的大模型开放评测体系
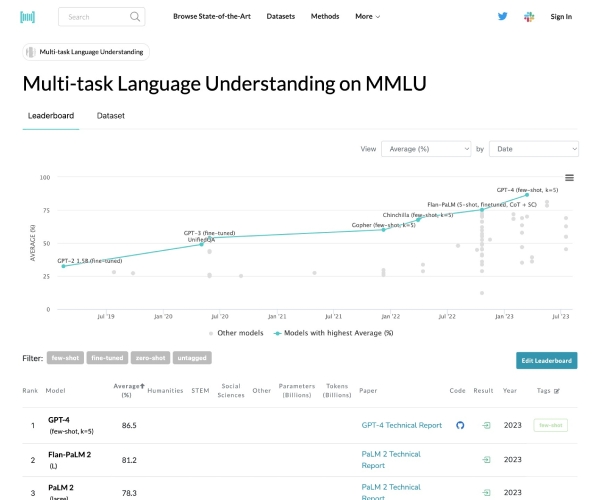
大规模多任务语言理解基准
智源研究院推出的FlagEval(天秤)大模型评测平台