斯坦福大学推出的大模型评测体系
HELM全称Holistic Evaluation of Language Models(语言模型整体评估)是由斯坦福大学推出的大模型评测体系,该评测方法主要包括场景、适配、指标三个模块,每次评测的运行都需要指定一个场景,一个适配模型的提示,以及一个或多个指标。它评测主要覆盖的是英语,有7个指标,包括准确率、不确定性/校准、鲁棒性、公平性、偏差、毒性、推断效率;任务包括问答、信息检索、摘要、文本分类等。
智源研究院推出的FlagEval(天秤)大模型评测平台
Hugging Face推出的开源大模型排行榜单
由复旦大学NLP实验室推出的大模型评测基准
一个全面的中文基础模型评估套件
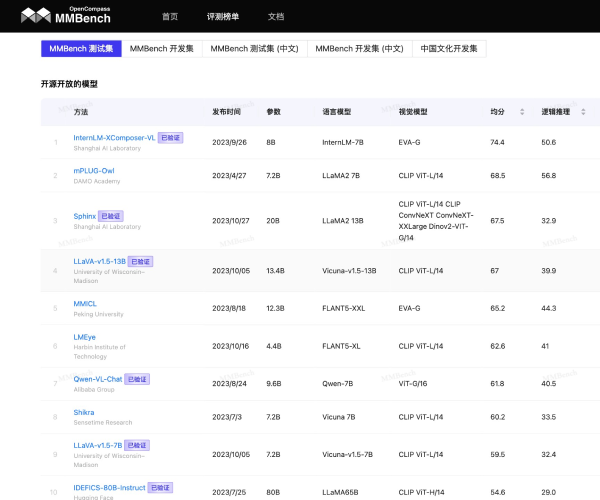
全方位的多模态大模型能力评测体系
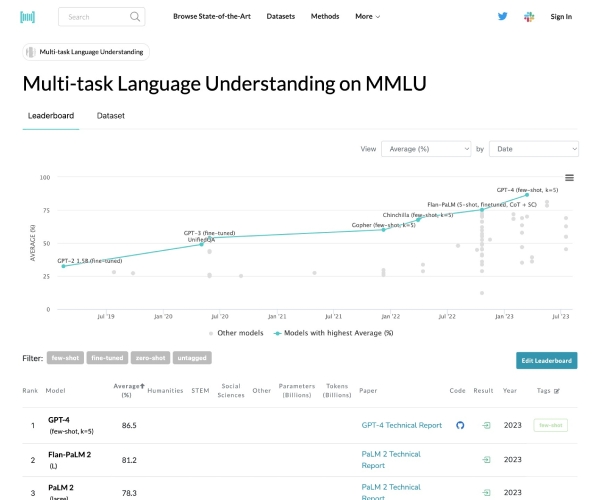
大规模多任务语言理解基准